Store sprogmodeller og sandsynlighedsteori
Store sprogmodeller, LLM, som eksempelvis ChatGPT bygger på, er ikke regnemaskiner og har ikke et lager af svar på spørgsmål, man stiller. Det er heller ikke meningen med dem. De kan skrive tekst, der ser fornuftig ud, og det er det, der er imponerende. Indimellem ”finder de på” ting ud af den blå luft – hallucinerer. De seneste hallucinerer mindre, men de gør det stadig, og man ved ikke, hvornår. Output fra en LLM er i store træk den tekst, der er mest sandsynlig som respons på input, når man kender enorme mængder af tekst. Det er en slags avanceret autocomplete. I det følgende gives først en meget forenklet version af, hvordan LLM fungerer. Længere nede i Fra tekst til vektorer går vi tættere på sandheden: Vi ser på det helt fundamentale for en LLM, nemlig dens matematiske repræsentation af ord og ord i sammenhæng. På AI-mat findes der materialer om sprogmodeller, bl.a. siden Simple sprogmodeller, som indeholder en meget naiv tilgang via betingede sandsynligheder og såkaldte n-grams. Der argumenteres også for, hvorfor det ikke virker.
I det følgende eksempel forsøger vi at gætte næste bogstav. Man kan bruge samme tilgang til at gætte næste ord. I stedet for at tælle bogstavskombinationer i ord, skal man så tælle kombinationer af ord i en tekst, som for eksempel denne tekst, hvor der er 28 forskellige ord. På AI-mat gennemgås er et eksempel hvor fire sætninger med seks forskellige ord analyseres, for at danne nye sætninger.
Eksempel: Træning på tre ord
Eksempel: Træning på tre ord
Med ordene dansk, Kansas og snask som træningsdata, er der 5 forskellige bogstaver, som bruges til at lave tre ord med i alt 16 bogstaver. Vi kan tælle antal gange hvert af de fem bogstaver, s, n, a, k og d optræder.

Hvis vi kun har den information, og gerne vil lave nye ord, vil et bud være, at bogstavet s skal bruges mest i vores nye ord – det udgør $\frac{5}{16}$ af bogstaverne i vores 3 kendte ord. Vi vil altså vælge $s$ med sandsynlighed $\frac{5}{16}$, $k$ med sandsynlighed $\frac{3}{16}$, $n$ med sandsynlighed $\frac{3}{16}$, $a$ med sandsynlighed $\frac{4}{16}=\frac{1}{4}$, og $d$ har kun sandsynlighed $\frac{1}{16}$. Nu kan vi lave nye ord ved at vælge bogstaver med de sandsynligheder, vi har her. Et lille eksperiment kunne være at slå med en 16-sidet terning og vælge:
- -s, hvis den lander på 1, 2, 3, 4 eller 5
- -a, hvis den lander på 6, 7, 8 eller 9
- -n, hvis man slår 10, 11 eller 12
- -k, hvis man slår 13, 14 eller 15
- -d, hvis man slår 16.
Terningkastene gav 2, 10, 14, 16, 5, 16. Det giver ordet SNKDSD. I et andet forsøg fik man 5, 2, 3, 16. Altså ordet SSSD. Det er ikke et godt bud på ord, med de bogstaver.
Vi kunne tage en meget stor mængde dansk tekst og finde ud af, hvor hyppigt de enkelte bogstaver optræder, se Tabel 5, men det ville nok heller ikke give gode nye ord.
Pointen er, at et godt bud på næste bogstav i et ord afhænger af, hvilke bogstaver, der allerede er i ordet.
Så vi kan se på par af bogstaver i vores tre ord. Kombinationer af to bogstaver optræder som i denne tabel:
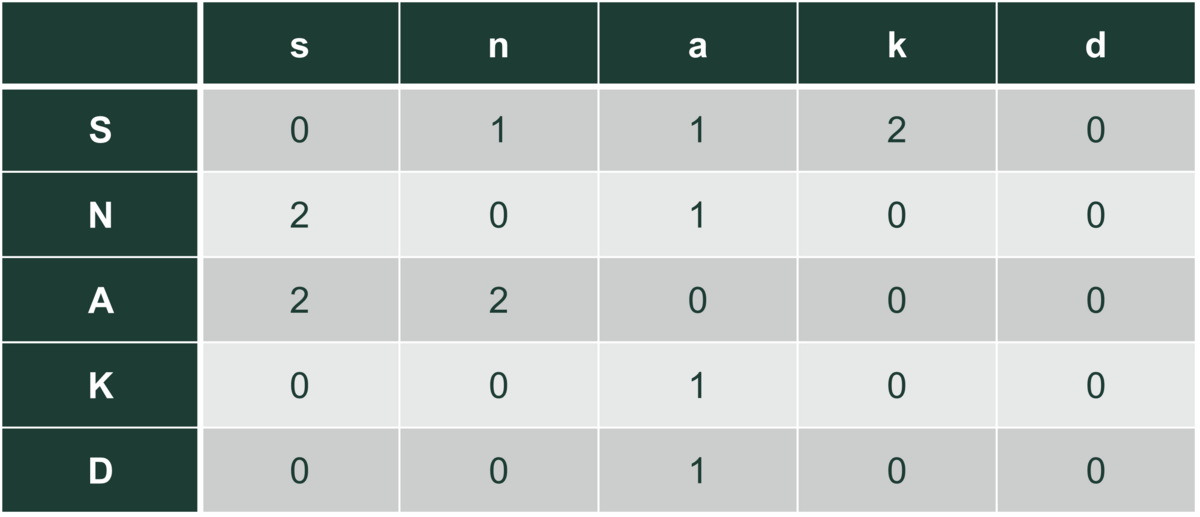
Hvis vi har et a, er der altså sandsynlighed $\frac{2}{4}=\frac{1}{2}$ for, at det næste bogstav er et s, og sandsynlighed $\frac{1}{2}$ for, at det næste er et n. Det er heller ikke supergodt til at lave autocomplete. Tilføjer vi bogstavet ”ingenting”, som svarer til start og slut af ord, får vi en ny tabel: To af vores tre ord ender med k, så k-, hvor – betyder ”ingenting”, optræder to gange, s- en gang. -s en gang, -k en gang og -d en gang. Det giver tabellen:
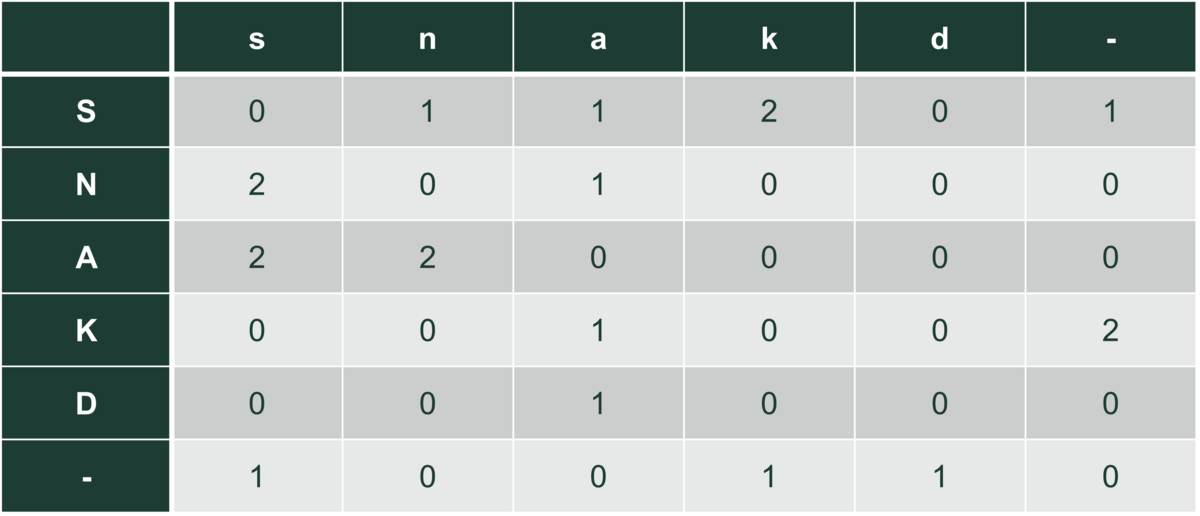
Vi kan også undersøge kombinationer af tre bogstaver – der er i alt $6^3=216$ muligheder, men de forekommer ikke alle sammen i vores tre ord. I tabel 4 udnytter vi, at vi fra tabel 3 kender de todelte bogstavssekvenser, som faktisk findes i vores tre ord:
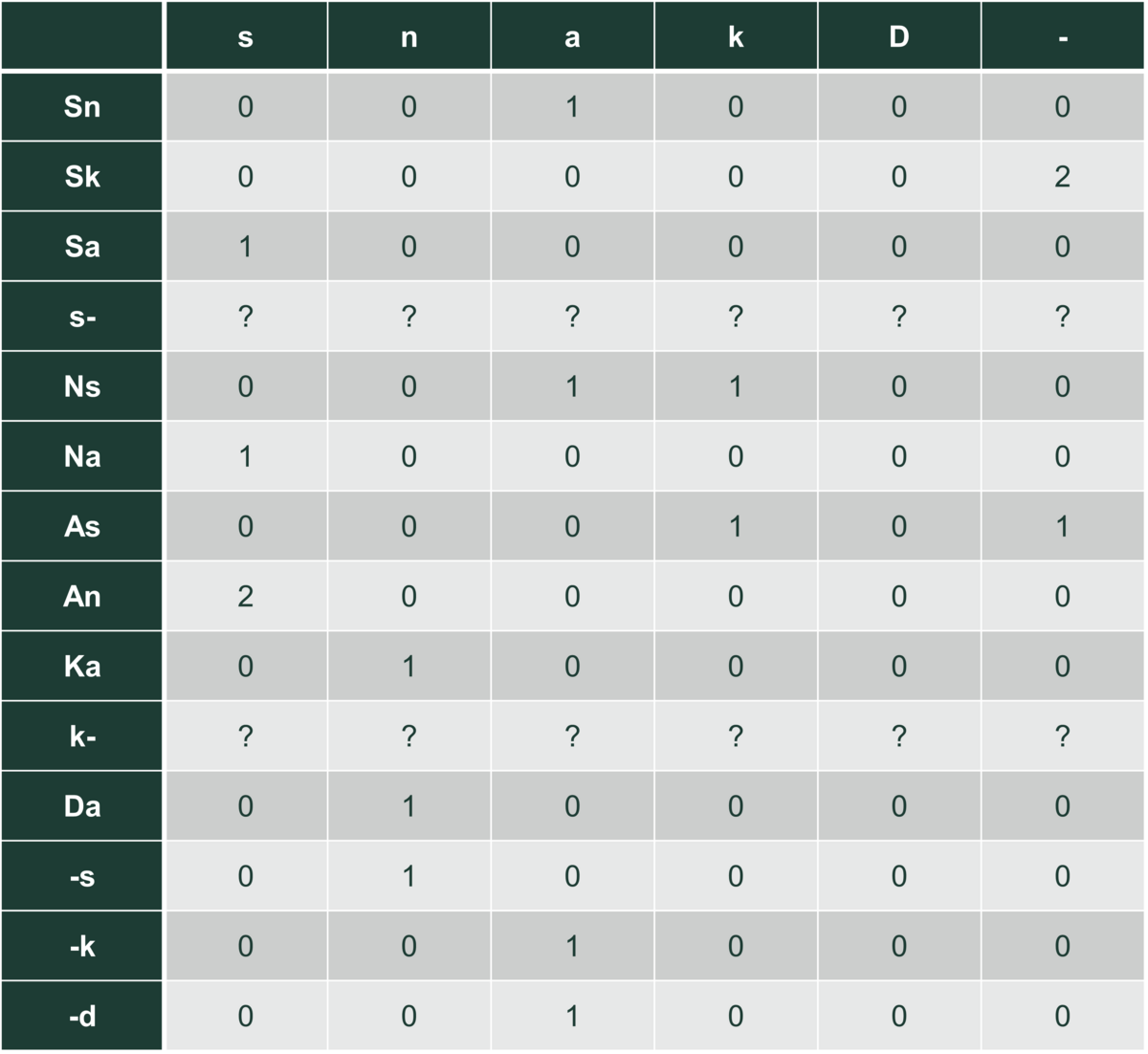
Tabellen viser, at hvis vi har set ”ns” i et af vores tre ord, vil der i $\frac{1}{2}$ af tilfældene følge et a og i $\frac{1}{2}$ af tilfældene et k. En primitiv autocomplete vil så vælge a med sandsynlighed $\frac{1}{2}$ og k med sandsynlighed $\frac{1}{2}$.
- a) Eleverne vælger et antal ord, finder hyppigheden af bogstaver, som i tabel 1, orddele med to bogstaver (se tabel 2 og 3) og med tre bogstaver (se tabel 4).
- b) Lav nu nye ord. Først ved at bruge hyppigheden af bogstaver. Det kan give anledning til overvejelser som: Hvad går galt, hvis man altid vælger det mest hyppige? (Svar: Det hyppigste bogstav er det eneste, der bliver brugt.) Hvad gør man, hvis to eller flere har samme hyppighed? (Trækker lod – slår med en terning.)
- c) Vælg næste bogstav ud fra hyppigheden ved tendenslodtrækning: For hvert ord, eleverne har valgt, laves et kort for hvert bogstav. Nu trækkes næste bogstav fra alle disse kort.
- d) Brug nu hyppigheden af orddele med to bogstaver på samme måde. Giver det bedre ”ord”?
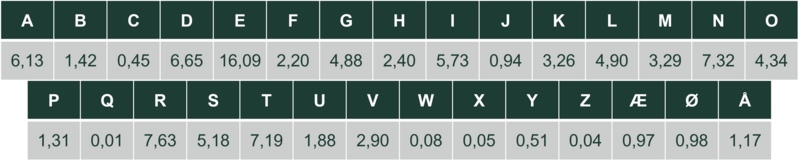
Hyppigheden af bogstaver i danske tekster ses i Tabel 5. Hyppigheden af orddele med 2 bogstaver er i Tabel 6. Det afhænger af, hvilke tekster, man tæller bogstaver og orddele i (kilde 1).

Aktivitet 2
Brug tabellen over orddele med to bogstaver, Tabel 6. Opskriv sandsynligheder for næste bogstav efter E ved først at finde alle mulighederne: EN, ER, ET, EL, ED. De udgør tilsammen $(3,66+3,63+2,15+1,06 + 1,24) % = 11,74%$ af alle to-bogstavsorddelene. Af disse udgør EN $\frac{3,66}{11,74}=0,312=31,2%$. Så hvis vi ved, første bogstav er E, så er der $31,2%$ sandsynlighed for at næste bogstav er N. Gør nu det samme for R, T, L og D.
Orddele med 3 bogstaver findes i samme kilde. De mest hyppige er FOR $1,24%$, DET $1,18%$, DEN $1,10%$.
I en stor sprogmodel ser man på ord i stedet for bogstaver, (Faktisk ser man på såkaldte ”tokens”, som kan være dele af ord eller kombinationer af små ord.) Man ser på en længere del af den tekst, der går forud, før man foreslår næste ord – ikke kun et enkelt ord eller to bagud. Lidt à la Googles gæt på næste ord, når man søger.
Eksempel
Matematik er … vigtigt $15\%$, sjovt $12\%$, svært $10\%$, nemt $7\%$, …. Hvor procenterne er sandsynligheden for, at hhv. vigtigt, sjovt, svært, nemt osv. er det næste ord.
En chatbot vil med en vis sandsynlighed vælge noget andet end ”vigtigt”. Jo mere kreativ, man vil være, jo højere sandsynlighed er der, for at den vælger noget andet. Den parameter, der bestemmer graden af kreativitet, kaldes ”temperaturen”. Hvis den er 0, vælges ordet ”vigtigt” altid. Hvis den er 1, vælges ordene med den sandsynlighed, de optræder med i træningsteksten. Det forlyder, at temperaturen er ca. 0,8 for de nyeste GPT-modeller. En anden mulighed, når man laver sig en stor sprogmodel, er, at de mindst hyppige ord i træningsteksten slet ikke kan vælges, uanset temperaturen.
Faktisk gør de store sprogmodeller noget, der er meget smartere end bare at kigge på, hvilke ”sætningsbidder”, man har i de enorme mængder tekst, korpus, som vi træner modellen på. Vi vil gerne have, at der er flere forslag til at afslutte ”Matematik er … ”, end dem, der allerede findes i korpus. Hvis der i korpus står ”Matematik er vigtigt”, men ikke ”Matematik er væsentligt”, vil vi gerne have, at sprogmodellen alligevel kan foreslå ”væsentligt”, fordi ordene ”vigtigt” og ”væsentligt” betyder nogenlunde det samme – og hvordan skal modellen så vide det? (OBS: Den ved ikke noget. Man skal passe meget på med at menneskeliggøre sine computerprogrammer).
Her skal man bruge sprogteori. Betydningen af et ord kan man se ud fra den kontekst – de sammenhænge – ordet optræder i.
Fra tekst til vektorer - transformeren
En stor sprogmodel trænes på meget store mængder tekst, et korpus. Der er måske $10^{12}$ ord i korpus for en stor sprogmodel. Man kan, som i ovenstående, tælle hvor hyppigt hvert ord optræder, eller hvilke ord, der kommer efter andre, men det ville ikke umiddelbart fortælle, at ordene ”vigtigt” og væsentligt” har nogenlunde samme betydning.
Den information, der skal lagres, er hvilke ord, der optræder i hvilke sammenhænge – det er det, der, ifølge sprogteori, fortæller, hvad ordene betyder. Den information skal komprimeres effektivt, så det væsentlige bibeholdes og så det kan findes frem effektivt. Det skal man have en matematisk model for, og det er den model, der er inkorporeret i de særlige kunstige neurale netværk, som kaldes transformere.
Sådanne netværk har mange milliarder koefficienter – man kan tænke på dem som tal i en funktion. Når vi repræsenterer data ved at bruge bedste rette linje, $y=ax+b$, er der to koefficienter, $a$ og $b$. Rygterne siger, GPT-4 anvender 1.700 milliarder koefficienter, men det præcise tal er hemmeligt.
At repræsentere disse tekstmængder smart er, sammen med designet af det kunstige neurale netværk – transformerarkitekturen - hele grundlaget for sprogmodellerne: Man repræsenterer information om, hvilke ord, der kan optræde i de samme sammenhænge – de ligner hinanden, er tæt på hinanden. Ord, der aldrig ses i samme sammenhæng, er langt fra hinanden. Hvert ord repræsenteres af en stribe tal, hvis der er 100 tal, kunne det skrives, ($a_1$, $a_2$, $a_3$, …., $a_{100}$). Det kaldes en vektor. Man kan regne på disse ordvektorer på nogenlunde samme måde, som vektorer med 2 eller 3 koordinater.
At oversætte ord til vektorer kaldes en ”embedding” – en indlejring – af ordene. Se AI-mats hjemmeside, hvor princippet bag en af de mulige indlejringer, Word2Vec, gennemgås.
Eksempel
En Word2Vec-model trænet på danske tekster, der stammer fra 1983 til 2019 (Kilde 2), fortæller, at de danske ord, der mest ligner ordet ”bredbåndsforbindelse”, er, i rækkefølge, internetforbindelse, netforbindelse, internetopkobling, fastnettelefon, opkobling. Nyere tekster ville formentlig have givet andre sammenhænge.
Når man har en indlejring, og giver sprogmodellen input, som den slet ikke har trænet på – man kan sige, den aldrig før har ”set” det input – kan den bruge indlejringen til at finde ord, der betyder nogenlunde det samme som input, og give et bud på output ud fra det. For eksempel kunne man have ”hundens madskål er i køkkenet” i træningsdata, men aldrig ”kattens madskål”. Ordene kattens og hundens vil ligge tæt på hinanden i indlejringen, og input ”kattens madskål” vil derfor give ”er i køkkenet” som en sandsynlig efterfølger.
Det er vektorregning og sandsynlighedsteori og altså gymnasiematematik, men i en helt, helt anden sammenhæng end eleverne plejer at se den. Det kan man læse mere om på https://aimat.dk.
til: GRUNDSKOLE, GYMNASIE, ERHVERVSUDDANNELSE
emne: AI
UDGIVET: 2025
Forfatter
Lisbeth Fajstrup
Lektor Emerita, ph.d.
Institut for Matematiske Fag, AAU
Udgiver
Temaer på matematikdidaktik.dk udvikles i tæt samarbejde mellem forskere og praktikere og udgives af NCUM.
Se redaktionen og vores redaktionelle retningslinjer
Kilder:
-
Dansk Sprognævn. (u.å.). De mest almindelige bogstaver i dansk. https://sproget.dk/sprogviden/sprogtemaer/ord-og-bogstaver-i-tal/de-mest-almindelige-bogstaver-i-dansk/
-
Det Danske Sprog- og Litteraturselskab. (u.å.). Word2vec – Ordmodeller. https://korpus.dsl.dk/resources/details/word2vec.html