Klassificering og afstandsbegreber
Ligner en grand danois en hest eller en hund?

Mennesker kan nemt se forskel på stole og borde, æbler og pærer, grise og hunde, heste og grand danoiser, muffins og chihuahuaer, men hvordan får man en computer til at gøre det samme? At skelne er fundamentalt for os og også for AI: scannere finder (potentielt) ulovlige ting i postpakker, automatisk styring af biler skal kunne se forskel på lastbiler og vejskilte, moderne kameraer fokuserer på personer osv.
Sammenligninger bygger ofte på (avancerede) matematiske afstandsbegreber: Noget data er allerede klassificeret – man kan tænke på billeder af hunde og heste. Et nyt eksempel kan sammenlignes med dem, vi kender facit for – er det ”tættest på” de kendte billeder af hunde eller på dem, vi ved er heste? I Klassificering og geometri opdeler vi træningsdata med linjer – man kan tænke sig, at hestene er på den ene side af linjen og hundene på den anden – og et nyt billede bliver så klassificeret som hest eller hund alt efter, hvilken side af linjen det ligger på.
Her ser vi på afstande i planen og foretager en meget simpel klassifikation, hvor vi har farvede punkter i planen og skal bestemme farven på et punkt, hvis farve vi ikke kender. Hvis koordinaterne i planen er henholdsvis. blodtryk og kolesterolindhold i blodet, kunne farven være sygdomme – diabetes, hjertearytmi og måske begge dele som den sidste farve. Vi forestiller os, at farven på punkterne hænger sammen med, hvor i planen de ligger. I afsnittet Andre afstande ser vi på afstande mere generelt. Den mest hensigtsmæssige afstand mellem datapunkter i planen behøver ikke være den, vi kender fra geometri. Der findes mange forskellige former for afstande, der er nyttige i forskellige situationer. Når vi eksempelvis skal måle afstand mellem ord, bliver vi nødt til at indføre et andet afstandsbegreb. Det helt generelle begreb, en metrik, kan man læse mere om på AI-mat.
Aktivitet: Punktafstand
Aktivitet: Punktafstand
Aktiviteten kan også findes på AI-mat.
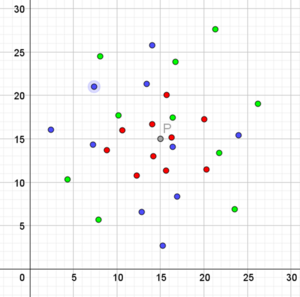
Vi kender farven på nogle punkter. Hvad er mon farven på det nye grå punkt $P$? Der er 10 røde, 10 grønne og 10 blå, så at tælle dem alle sammen og give $P$ samme farve, som dem, der er flest af kan man ikke. En tilgang er at se på dem, der er tættest på.
Eleverne kan overveje, hvilke punkter man skal tage med. Hvad med det ene blå punkt, der ligger tæt på? Er der flest røde tæt på? Og hvad mener vi med tæt på? Er det blå punkt med skyggen tæt nok på til at skulle tages med i overvejelserne?
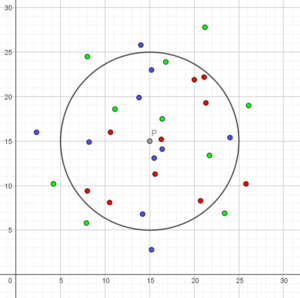
Eksempel: Tæt på må være inden for en cirkel med passende lille radius. Punkter indenfor cirklen tælles – hvor mange blå, røde, grønne er der? Kan det bruges til at afgøre, hvad farve det grå punkt formentlig har?
Opgave: Variér radius i cirklen og overvej, hvad radius i cirklen betyder for den farve, vi giver det grå punkt. Benyt for eksempel AI-mats app.
For at finde den ”bedste” radius til klassifikation af det nye punkt, vil man udnytte krydsvalidering, hvor de kendte data (træningsdata) også benyttes som testdata. Hvis vi kender farven på 500 punkter, lader vi de 100 være testdata. Vi anvender de resterende 400 som træningsdata og klassificerer testpunkterne ét ad gangen ved hjælp af den beskrevne metode ovenfor. På den måde kan man undersøge, hvordan klassifikationen fungerer ved forskellige valg af radius. Den radius, der giver den laveste fejlprocent - altså flest korrekt klassificerede testpunkter – vælges til klassifikation af nye, ukendte punkter.
De k-nærmeste naboer:
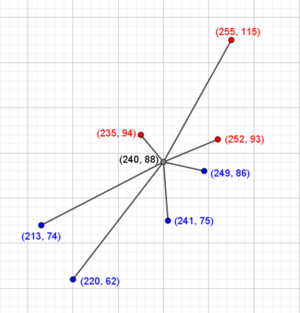
I stedet for at beslutte sig for en radius, kunne man beslutte sig for, hvor mange nabopunkter, man vil tage med og give det nye punkt den farve, de fleste naboer har.
Er det nye punkt blåt eller rødt? Hvis man fokuserer på de 3 nærmeste naboer, er der to røde og et blåt og man vil sige, at det nye punkt skal klassificeres som rødt. Ser man i stedet på de 7 nærmeste naboer, er de alle sammen med, og så bliver det nye punkt klassificeret som blåt.
Se dette indgå i et stort eksempel her.
Opgave: Beregn afstandene fra det nye punkt til hvert af de øvrige punkter. Klassificér derefter punktet ud fra de 5 nærmeste naboer. Hvad sker der, hvis du kun bruger den allernærmeste nabo?
Opgave: Plot to punkter i planen og giv dem forskellige farver: ét blåt og ét rødt. Hvis et nyt punkt klassificeres efter den nærmeste nabo, hvor i planen skal det så placeres for at blive klassificeret blåt? Hvor går grænsen mellem at blive klassificeret som rødt og som blåt? Vink: Grænsen er en linje, der deler planen i to områder.
Andre afstande
Den mest nærliggende måde at måle afstand mellem data er ofte den euklidiske afstand, altså den vi beregner med Pythagoras: $d((x_1,y_1),(x_2,y_2))=\sqrt{(x_1-x_2)^2+(y_1-y_2)^2}$. Men det er ikke altid den mest fornuftige. Forestil dig fx en person A, som vejer 70 kg og er 1,65 m høj. Ligner A da mest person B, der vejer 90 kg og er 1,80 m eller person C, der vejer 80 kg og er 1,90 m? Ligner mest skal svare til ”har kortest afstand til”. Hvis vi blot plotter punkterne i et (vægt, højde) koordinatsystem og beregner med Pythagoras, får vi afstanden fra A til B til at være ca. 20, mens afstanden fra A til C er ca. 10. Måler vi nu højden i centimeter, bliver afstanden fra A til B mindre end afstanden fra A til C. Så det er ikke klart, hvordan de tre datapunkter skal sammenlignes (se mere om skalering).
Afstande er dermed mere komplicerede end den sædvanlige afstand mellem punkter i plan og rum. Selv når data ikke umiddelbart er ”tal”, kan man alligevel definere afstande. Det ser vi på i Afstande mellem ord.
Afstandsbegrebet er meget generelt og omfatter afstande mellem funktioner, mellem (visse) delmængder i planen og meget mere. Dette generelle begreb kaldes en metrik. Det kan man læse om her. De afstande, vi har med nedenfor, er alle sammen eksempler på metrikker.
Aktivitet: Afstande mellem ord
Aktivitet: Afstande mellem ord
Ord eller lange strenge af 0’er og 1’er sammenligner man i forskellige sammenhænge: For eksempel ved korrektion af fejl, der er opstået i en kommunikation med ”støj” på, eller når man sammenligner DNA-strenge, som kan opfattes som tekst med bogstaverne GATC.
Strengafstande – edit-afstande.
- Hammingafstand: Afstanden mellem ordene ’sok’ og ’sko’ er 2, da bogstav nummer 2 og bogstav nummer 3 begge er forskellige. Mere præcist: Hammingafstanden mellem to ord med lige mange bogstaver er det antal pladser, hvor bogstaverne er forskellige. Det er antallet af bogstavskift, man skal lave for at komme fra det ene ord til det andet.
- Levenshteinafstand: Afstanden defineres her også som det antal ændringer, man skal lave, for at nå fra det ene til det andet ord, men der er flere tilladte ændringer. Man må ændre ét bogstav ad gangen ligesom i Hammingafstand, men man må også indsætte eller fjerne bogstaver. Der er stadig afstand 2 fra ’sok’ til ’sko’, men fra ’post’ til ’oste’ kan man ændre ’post’ $\to$ ’ost’ $\to$ ’oste’ og se, at Levenstheinafstanden er 2, mens Hammingafstanden er 4.
- Levenshtein-Damerau: Her må man også ombytte bogstaver. Afstanden fra ’sok’ til ’sko’ er dermed kun 1 (man kan ombytte k og o), mens der stadig er 2 ændringer fra post til oste.
Levenshtein og Levenshtein-Damerau giver i modsætning til Hammingafstanden mening for ord med forskelligt antal bogstaver.
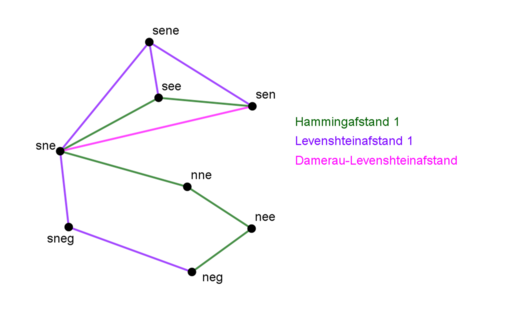
Aktivitet: Skriv ord på tavlen og forbind dem via de forskellige ”moves”, der er tilladt. Benyt først Hamming-moves. Hvilke nye moves får man med Levenshtein? Tegn de nye forbindelser med en anden farve. Hvilke nye moves får man med Damerau? Tegn de forbindelser i en tredje farve.
Hamilton, Levenshtein og Levenshtein-Damerau kaldes edit-afstande. Man finder afstand ved at finde den korteste vej i et netværk som det på figur 5, hvor hver forbindelse er et ”edit-move”.
Edit-afstande mellem DNA og RNA er lidt anderledes. De tilladte moves svarer til mutationer, men de har forskellig ”pris”, som afhænger af, hvor sandsynlige de forskellige mutationer er. Så afstanden fra GATC til GATT afhænger af, hvor sandsynligt det er, at der sker mutation fra T til C. Se mere om at måle på afstande for DNA og find et helt undervisningsforløb om DNA-sammenligning.
Eksempel
Eksempel
To punkter $P$ og $Q$ i planen med koordinater henholdsvis $(x_1, y_1)$ og $(x_2, y_2)$ har ifølge Pythagoræisk afstand
$\sqrt{(x_2-x_1)^2+(y_2-y_1)^2}$
Det kaldes også den euklidiske afstand. Men der er andre afstandsbegreber i planen. Manhattanafstanden eller taxi-afstanden er den afstand, man får, når man er nødt til at gå langs akserne – mellem husblokke – og den er
$|x_2-x_1|+|y_2-y_1|$
En anden mulighed er at sige, afstanden er den største af de to koordinatafstande, maksimum af $|x_2-x_1|$ og $|y_2-y_1|$. Det kaldes også Chebyshev-afstand, Max-afstand eller skak-kongeafstanden (det mindste antal træk, en konge i skak skal bruge for at nå fra $P$ til $Q$).
Med $P(3,4)$ og $Q(7,7)$ bliver den euklidiske afstand 5, Manhattanafstanden er 7, Max-afstanden er 4.
På AI-mat er der mulighed for at flytte rundt på to punkter i planen og se, hvad de tre afstande bliver.
Opgave
Opgave
- Afsæt tilfældige punkter, P og Q, i planen og udregn de tre forskellige afstande mellem dem.
- Overvej, hvordan skakkongen kan bevæge sig fra P til Q med færrest mulige skridt. (Det gælder om at gå så meget diagonalt som muligt).
- Hvordan ser ”cirkler” mon ud, når vi bruger de nye metrikker? En cirkel med centrum C og radius r, er de punkter, der har afstand r til punktet C. Med nye afstande ser cirkler anderledes ud:
- Tegn de punkter, som har Manhattanafstand 2 til Origo. Det er cirklen med radius 2, når metrikken er Manhattanafstanden.
- Tegn de punkter, der har Max-afstand 2 til Origo. Det er cirklen med radius 2, når metrikken er Max-afstanden.
til: GRUNDSKOLE, GYMNASIE, ERHVERVSUDDANNELSE
emne: AI
UDGIVET: 2025