Hierarkisk klyngedannelse
Klyngedannelse (clustering) af data kan gøres på flere måder, men grundtanken er altid, at man vil samle data i ”klumper” (klynger), hvor hvert datapunkt har kortere afstand til de andre i klyngen end til dem i en anden klynge. På den måde kan man afdække mønstre eller sammenhænge, som ikke umiddelbart var synlige før. Det er uden opsyn (unsupervised) og bruges for eksempel til markedsanalyse, hvor man kan identificere forbrugergrupper eller generere anbefalinger ud fra lignende købsadfærd (”andre, der har købt det, du har købt, har også købt…”). Når der er lavet en klyngeanalyse, kan man finde ud af, hvilken klynge et nyt datapunkt hører til, og udnytte, at det nye datapunkt formentlig deler egenskaber med de øvrige i klyngen.
Et eksempel på klyngedannelse kan findes inden for biologien. Her kan man beregne afstande mellem DNA-sekvenser og på den baggrund konstruere de såkaldte fylogenetiske træer, som illustrerer, hvordan arter nedstammer fra hinanden. Dette gøres ofte ved hjælp af hierarkisk clustering, men der findes også andre metoder, se mere her.
Afstanden mellem to DNA-strenge kan man definere på flere måder (se Klassificering og afstandsbegreber). Selv hvis data er punkter i plan eller rum, kan man bruge andre afstande end den, vi er vant til. Se afsnittet Andre afstande.
Ved klyngedannelse tager man udgangspunkt i de parvise afstande mellem datapunkter, uden nødvendigvis at kende eller bruge information om deres placering i planen, rummet eller andre dimensioner. Data kan endda være af en sådan karakter, at de slet ikke har koordinater og derfor ikke ligger i et geometrisk rum, men alene beskrives gennem deres indbyrdes afstande.
Eksempel: Punkter i planen
Eksempel: Punkter i planen
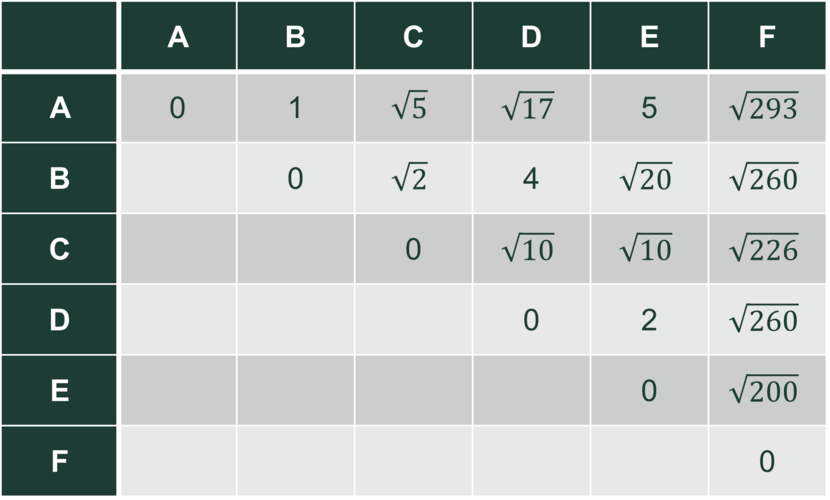
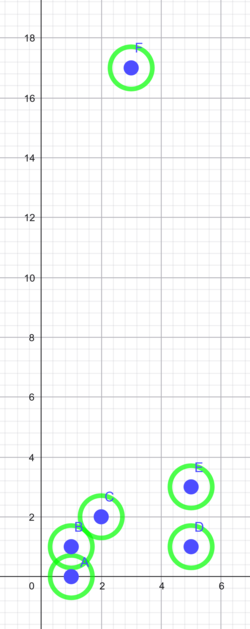
Vi har punkter i planen: A= (1,0), B= (1,1), C= (2,2), D= (5,1), E= (5,3) og F= (3,17).
De parvise afstande kan vi holde styr på i en tabel, hvor vi kun behøver udfylde det over diagonalen eller det under diagonalen (hvorfor?).
Herfra kan klyngdannelsen påbegyndes
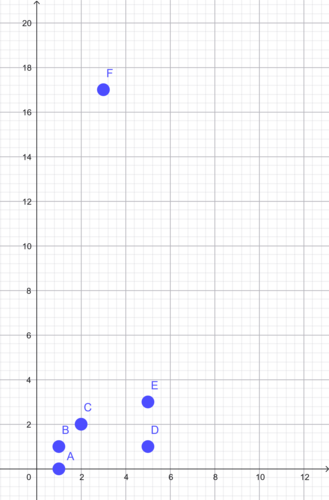
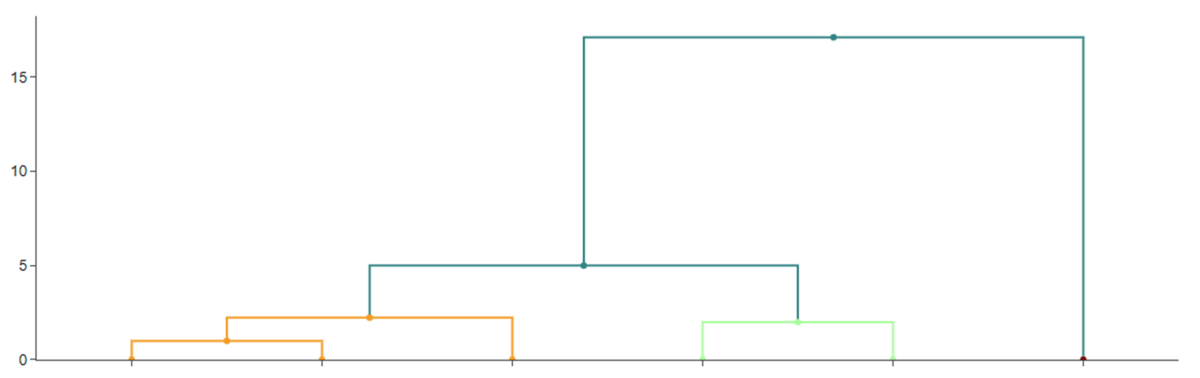
- Trin 1: Alle punkter er i hver deres klynge.
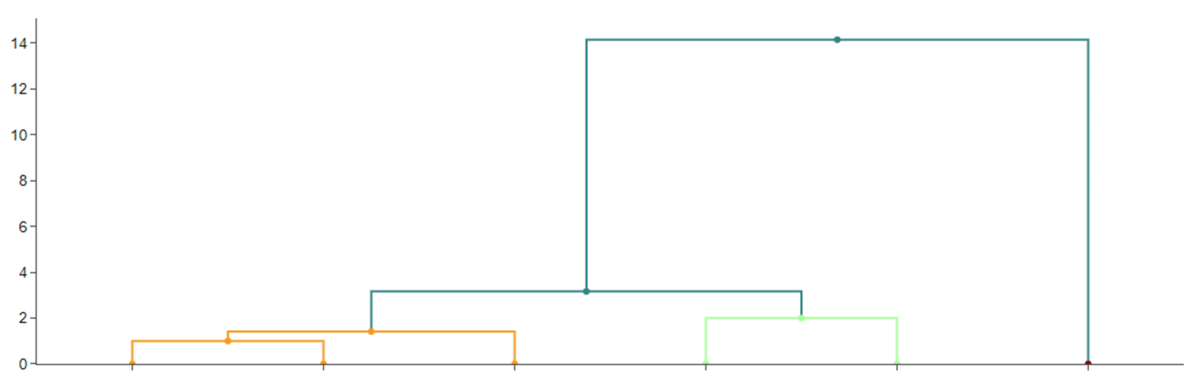
- Trin 2: Find den mindste afstand og lav en klynge med de punkter, der har denne parvise afstand. Her kommer $A$ og $B$ i klynge, da 1 er den mindste afstand. Kald den klynge $AB$.
- Trin 3: Afstanden fra $B$ til $C$ er den næstmindste, men $B$ er i klynge med $A$. Så hvad er afstanden fra $C$ til klyngen $AB$? Vi vælger at sige, afstanden fra $C$ til $AB$ er den mindste af afstandene $C$ til $A$ og $C$ til $B$. Det kaldes ”single linkage”. Så $C$ sluges nu i klyngen, og vi har klyngen $ABC$, når vi er nået til højden $\sqrt{2}$ – se dendrogrammet i Figur 2.
- Trin 4: I højde 2 dannes klyngen $DE$.
- Trin 5: I højde $\sqrt{10}$ mødes klyngerne $ABC$ og klyngen $DE$ og danner klyngen $ABCDE$ (fordi afstanden fra $C$ til $D$ er $\sqrt{10}$. Det er også afstanden fra $C$ til $E$, men det er ok. Vi leder efter den mindste afstand).
- Trin 6: I højde $\sqrt{200}$ mødes klyngen $ABCDE$ med $F$. Nu er alle datapunkter én stor klynge.
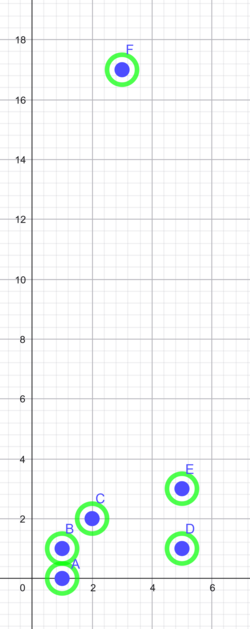
Hvis vi gerne vil have data delt i tre klynger, skal vi stoppe i en højde mellem $2$ og $\sqrt{10}$, hvor vi har klyngerne $ABC$, $DE$ og $F$. Beder vi om to klynger, får vi $F$ alene og de andre i en samlet klynge.
Opgave: Hvad er sammenhængen mellem radius af cirkler og klyngedannelse?
- Tegn cirkler med radius $\frac{\sqrt{2}}{2}$ omkring alle punkterne $A$, $B$, $C$, $D$, $E$, $F$. Kan I genfinde de klynger, vi har i højde$\sqrt{2}$ i dendrogrammet? Hvad med højde $\sqrt{2}$ ? (Svar: Cirkler med radius $\frac{\sqrt{2}}{2}$ og centrum i hhv. $A$, $B$ og $C$, vokser sammen. Cirklerne omkring $A$ og $B$ er allerede vokset sammen ved radius $\frac{1}{2}$.)
- Hvad er sammenhængen mellem cirkler med voksende radius og klyngedannelsen? (Svar: To klynger bliver slået sammen til én, når én af cirklerne fra den ene klynge ”møder” én af cirklerne fra den anden i et fælles punkt.)
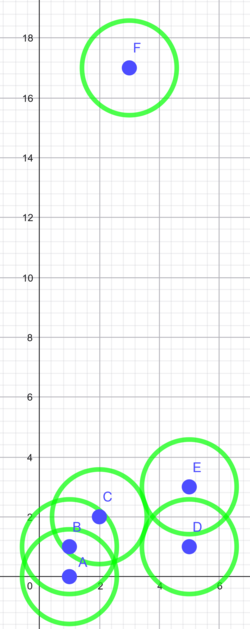
Afstanden mellem klynger kan vælges til ”complete linkage”, hvor afstanden fra $AB$ til $C$, når vi danner klyngen $ABC$, er den største af de to afstande, fra $C$ til $A$ og fra $C$ til $B$, altså $\sqrt{5}$, så ændrer man i dette eksempel ikke på, hvilke klynger, der opstår, men da klynge $ABC$ opstår ved $\sqrt{5}$, og klynge $DE$ opstår ved 2, er $ABC$ før $DE$. Hvis man ønsker 4 klynger, får man med single linkage klyngerne $ABC$, $D$, $E$ og $F$ – i højde mellem $\sqrt{2}$ og 2, mens man med complete linkage får $AB$, $C$, $DE$ og $F$ – i højde mellem 2 og $\sqrt{5}$.
Opgave: Hvad er sammenhængen mellem radius af cirkler og klyngedannelse med complete linkage?
- Hvis man tegner cirkler omkring hvert punkt og lader radius vokse, hvilke cirkler skal så mødes for at klynge $AB$ skal smelte sammen med $C$? Vi ved, at cirklen omkring $C$ skal møde både cirklen omkring $A$ og omkring $B$.
Aktivitet:
Lav en tabel over afstande mellem noget data, I selv har fundet på. Det behøver ikke være konkrete punkter i planen – der er mange afstande mellem data. Lav så en klyngeanalyse med tilhørende dendrogram.
- Er der forskel på de forskellige muligheder for afstande mellem klynger?
- Kan man ud fra et dendrogram finde parvise afstande, der ville give det dendrogram? Er der flere muligheder?
Eksempel: Klyngeanalyse af eksamenssæt
Eksempel: Klyngeanalyse af eksamenssæt
Ved evalueringen af skriftlig studentereksamen på stx og hf har man tidligere lavet en klyngeanalyse, hvor spørgsmålene i eksamenssættet tildeles en afstand bestemt af, hvordan hver enkelt elev har klaret dem. Det giver et indblik i, om der er en passende mængde nemme og svære opgaver, om opgaver med og uden hjælpemidler falder forskelligt ud osv.. Det følgende er en forsimplet version med meget få elever. Man ville normalt bruge en anden afstand, men princippet er grundlæggende i orden.
Hvis der er 7 spørgsmål og 5 elever, får man for hvert spørgsmål 5 tal, svarende til point for hver elev.
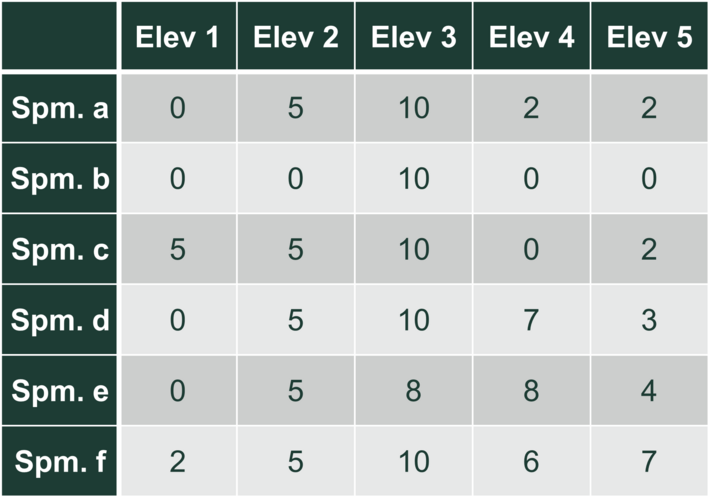
Afstand mellem spørgsmålene kan vælges på flere måder. Her bruger vi Manhattanafstand, som er nem at have med at gøre. Man lægger den numeriske forskel på elevernes score i de to opgaver sammen, f.eks.:
- Afstand mellem $a$ og $b$ er $0+5+0+2+2=9$
Afstandstabellen er dermed
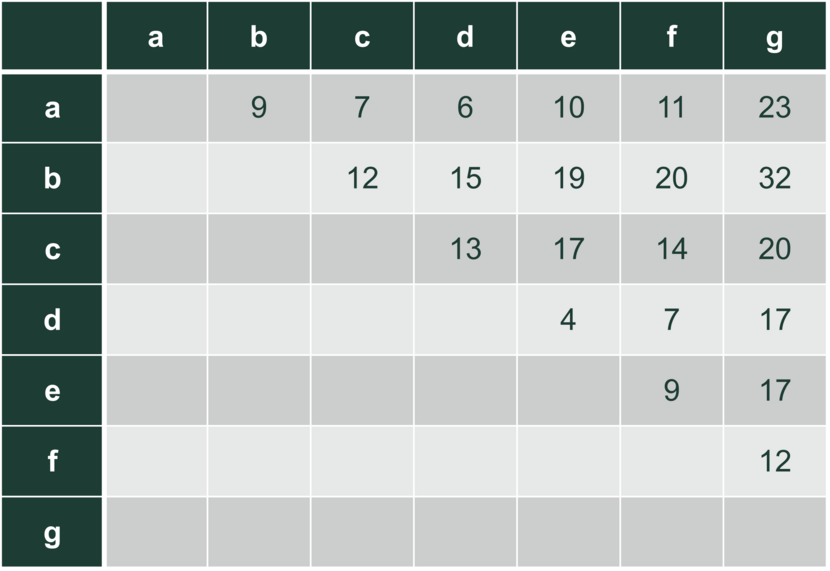
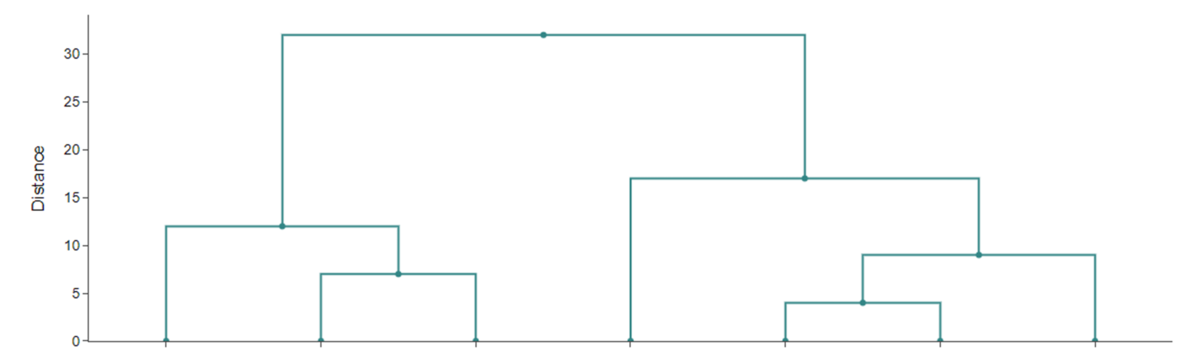
Lav herfra et dendrogram, og benyt så complete linkage til at bestemme klyngerne. Hvis man beder om to klynger, er det $abc$, som mødes i højde 12 og $defg$, som mødes i højde 17. Tre klynger giver $abc$, $def$ og $g$.
Se figur 7 og 8, hvor dendrogrammer for Manhattan-afstand og hhv. complete og single linkage kan sammenlignes
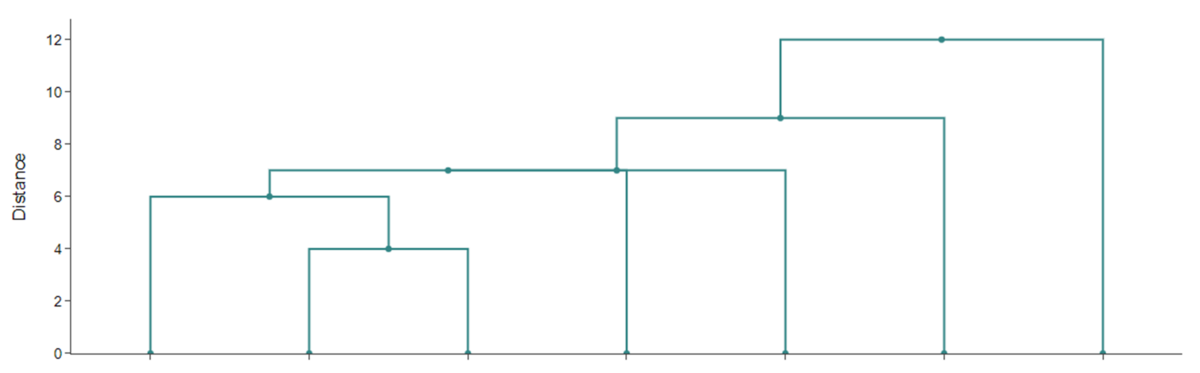
Aktivitet:
Brug data om eksamensopgaver til en klyngeanalyse af eleverne. Overvej, om det giver mere, bedre eller anderledes information end for eksempel at se på de enkelte elevers samlede antal point. Se for eksempel på elev 2 og 4. Deres samlede score er hhv. 30 og 32. Manhattanafstanden er $3+5+2+3+1+4=18$. Hvorfor er den ikke $32-30=2$?
Hvorfor har man mon brugt klyngeanalyse (af opgaverne) til at se, om det er et godt eksamenssæt?
Spørgsmål til lærerne:
- Det kræver matematisk indsigt at forstå den information, der er indeholdt i dendrogrammer – såsom: Hvorfor kan man finde opdeling i forskellige antal klynger ved at se på dendrogrammet i forskellige højder? Kan den indsigt styrke og underbygge matematik på grundskoleniveau? I gymnasiet?
- I eksemplet med eksamensopgaver har datapunkterne, som her er eksamensopgaverne, 5 koordinater. Giver det et nyt syn på vektorer?
til: GRUNDSKOLE, GYMNASIE, ERHVERVSUDDANNELSE
emne: AI
UDGIVET: 2025