Klassificering og geometri
I Klassificering og Afstandsbegreber har vi på forhånd kendskab til en del af data – fx billeder af hunde og billeder af heste. Den information bruger vi til at forudsige, hvad nye billeder forestiller. Under træningen justerer computeren sit bud på, hvad billeder forestiller, så den videst muligt rammer nogenlunde rigtigt i de tilfælde, hvor facit allerede er kendt. Denne tilgang kaldes læring under opsyn (supervised learning). Man kan også lade computeren selv komme med konklusioner fra data – fx ved at gruppere billederne. Altså lade computeren opdage, at nogle billeder ligner hinanden mere end de ligner andre. Det kaldes læring uden opsyn (unsupervised learning). Læs mere om gruppering (clustering) i Hierarkisk gruppering.
Her ser vi igen på læring under opsyn, men i stedet for at klassificere ud fra afstand til kendte data – som i Klassificering og afstandsbegreber, forsøger vi at opdele planen ud fra placeringen af træningsdata.
Algoritmer, der kan adskille punkter i kategorier som ”på den ene” eller ”på den anden side”, kaldes Support Vector Machines eller SVM. I dette enkle eksempel kan data opdeles med en ret linje, og der findes faktisk en linje, der skiller de to grupper. Generelt vil nogle punkter dog ligge på ”den forkerte side” – både fordi målinger kan indeholde støj, og fordi en simpel linje ikke altid er en perfekt model.
Rette linjer og klassifikation
Lad os se på en meget simpel form for data, som repræsenteres med punkter i planen. De to koordinater kan fortolkes som egenskaber ved data - fx højde og vægt eller blodtryk og kolesterolindhold - og man ved desuden, om disse personer har diabetes.
Det første og mest simple kunstige neurale netværk, perceptronen, forsøger at opdele den slags data ved at finde en linje, der deler data i to – på den ene og den anden side af linjen – hvor de syge er på den ene side, og de raske på den anden. Det kan man læse mere om på AI-mat, hvor vi bruger et mere samfundsfagligt eksempel (kandidattest).
Matematikken, der bruges, er rette linjer i planen ud fra et geometrisk synspunkt: En linje kan godt være parallel med y-aksen og altså eksempelvis have ligning $x=7$, så ”linjens ligning er $y=ax+b$” er ikke nok her.
For også at kunne beskrive lodrette linjer anvender vi i stedet ligninger af typen $cx+dy=e$. Det giver et nyt perspektiv, som vi udnytter ved at definere en funktion af to variable $f(x,y)=cx+dy$. Linjen udgøres da af de punkter, hvor $f(x,y)=e$. Linjen opdeler planen i punkter, hvor $f(x,y) >e$, $f(x,y)<e$ og dem på linjen.
Eksempel
Eksempel
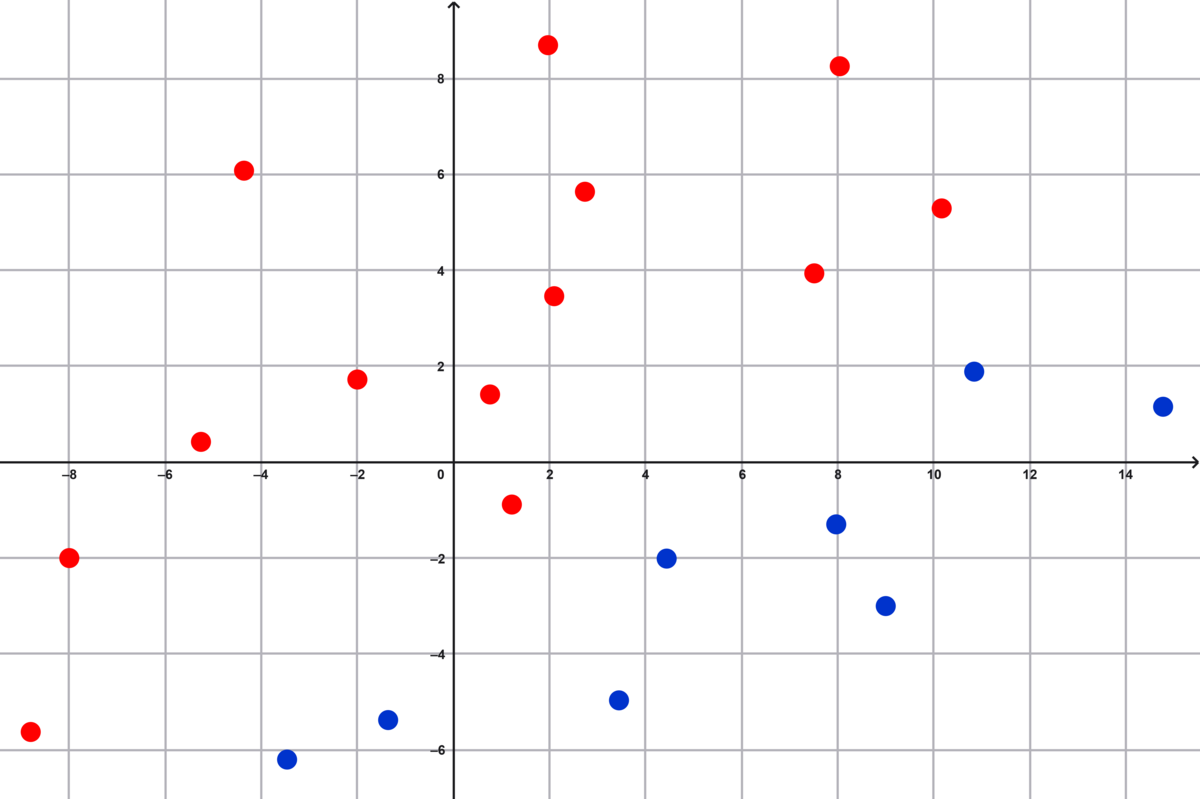
Data repræsenterer blodtryk og alder. De røde punkter på figur 1 er mennesker, der er syge, de blå er raske. Vi vil gerne kunne diagnosticere en ny person.
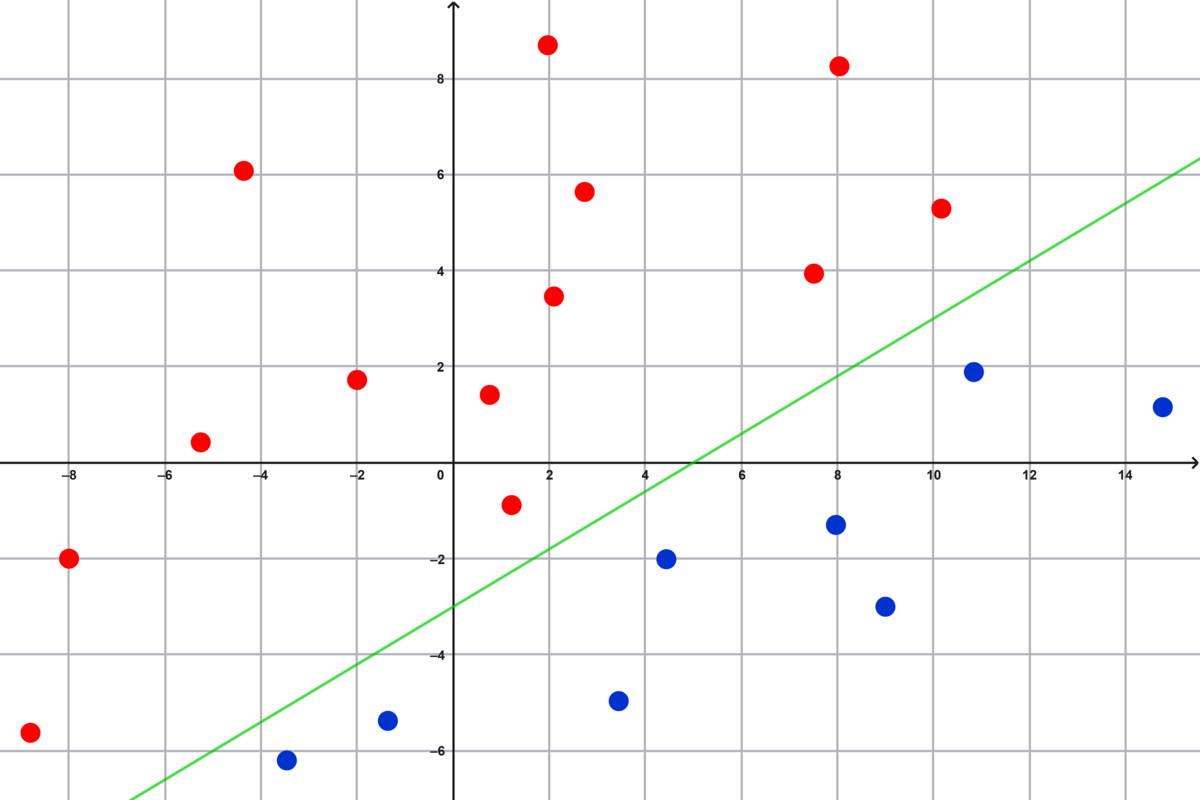
Den grønne linje med ligning $3x-5y=15$ deler planen, så de blå punkter ligger på den ene side, og de røde på den anden. De blå punkter opfylder $3x-5y>15$. De røde opfylder $3x-5y < 15$.
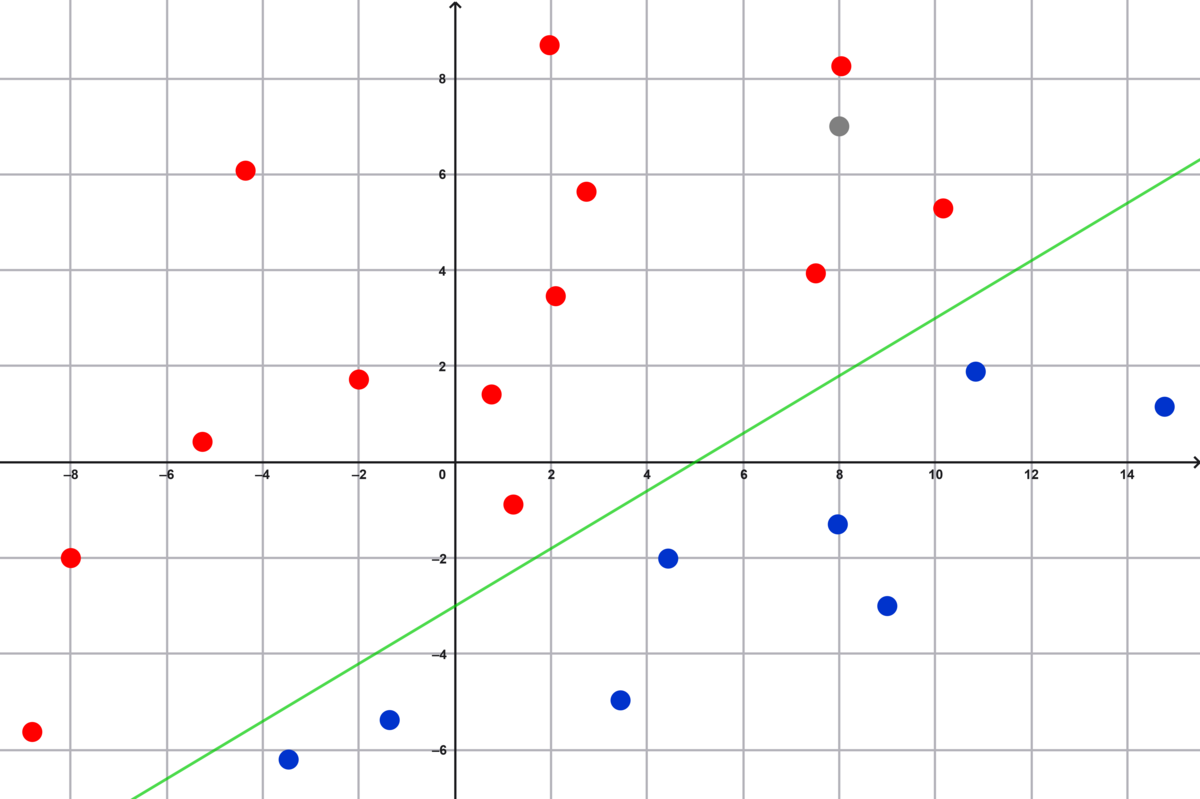
Vi kender blodtryk og alder for en ny person. Det er det grå punkt på figur 3. Vi kan se på figuren, at punktet ligger over linjen og formentlig repræsenterer en person, der er syg.
Hvis en computer skulle give svaret, kunne man bruge koordinaterne for det grå punkt, $(8,7)$, udregne $3x-5y$, som her giver $24-35=-11$, og konkludere, at punktet ligger ”over” linjen.
Aktivitet: Linjer i planen
- Lav linjer i planen og find deres ligninger på formen $cx+dy=e$
Tegn linjer, som opfylder $cx+dy=e$. F.eks. $2x+y=-1$, $x=4$, $4x+2y=-2$, $-2x-y=1$, $y=5$, hvor eleverne kan opdage svaret på næste spørgsmål:
- Overvej, om samme linje kan have forskellige ligninger. Hvordan kan man se på to ligninger, om det vil give samme linje?
- Se på eksemplet med de røde og grønne punkter. Indse, at $5y-3x=-15$ også er en ligning for linjen. Hvilken ulighed svarer nu til, at et punkt ligger på samme side som de røde punkter?
- Tegn linjerne $x+y=2$, $-2x+y=1$, $y=1$, $x=-2$.
- Beskriv linjer med ligning $cx+dy=e$ i forskellige tilfælde:
- a) $c$ og $d$ er begge positive.
- b) $c$ er positiv og d er negativ
- c) $c$ er negativ og d er positiv
- d) $c$ og d er begge negative.
- e) $c=0$
- f) $d=0$
- Hvilke af tilfældene ligner hinanden? Hvad er betydningen af tallet ”$e$”?
- Hvordan kan man opdele planen i ”på den ene side af linjen” og ”på den anden side af linjen”? (Svar: Punkter, der opfylder $cx+dy>e$ og punkter, der opfylder $cx+dy <e$)
- Hvad har det med normalvektorer til linjen at gøre?
- Hvordan hænger afstand til linjen sammen med $f(x,y)$? (Svar: Den er $|f(x,y)-e|$)
Rumgeometri
Hvis man har data med tre koordinater, opdeles de med planer. Ligningen er nu $ax+by+cz=d$. Hvordan ser man, om et givet punkt er på den ene eller den anden side af sådan en plan?
Til lærerne
- Kunne (dele af) ovenstående laves undersøgelsesbaseret?
- Tror (troede) jeres elever, at alle linjer i planen har en ligning på formen $y=ax+b$? Hvorfor gør (gjorde) de det?
til: GRUNDSKOLE, GYMNASIE, ERHVERVSUDDANNELSE
emne: AI
UDGIVET: 2025