Kunstige Neurale Netværk og funktioner
De store sprogmodeller, som er grundlaget for f.eks. ChatGPT, bygger på kæmpestore datamængder. At uddrage og anvende den struktur, der ligger i sådanne enorme datamængder, kræver smarte metoder. Et meget effektivt overordnet værktøj er kunstige neurale netværk, som ”trænes” på de data, man har, med henblik på at kunne analysere nye data.
Et kunstigt neuralt netværk kan, når det er ”trænet”, modtage input, såsom billeder, tekst, lyd etc. og for eksempel genkende ansigter, stemmer, forfattere, spam-e-mails eller andet. Der er altså tale om en matematisk funktion med komplekst input, hvor output eksempelvis kan være et ja/nej-svar på, om en e-mail er spam, eller en sandsynlighed for, at det næste ord efter ”Om morgenen tager jeg mig en …” er enten ”løbetur” eller ”lur”.
Funktionen er bygget op ud fra træningsdata. Data, hvor vi kender svaret. Det gælder så om at lave en funktion, der giver nogenlunde korrekt svar for træningsdata. Det er træning af netværket. Se også Klassificering og geometri.
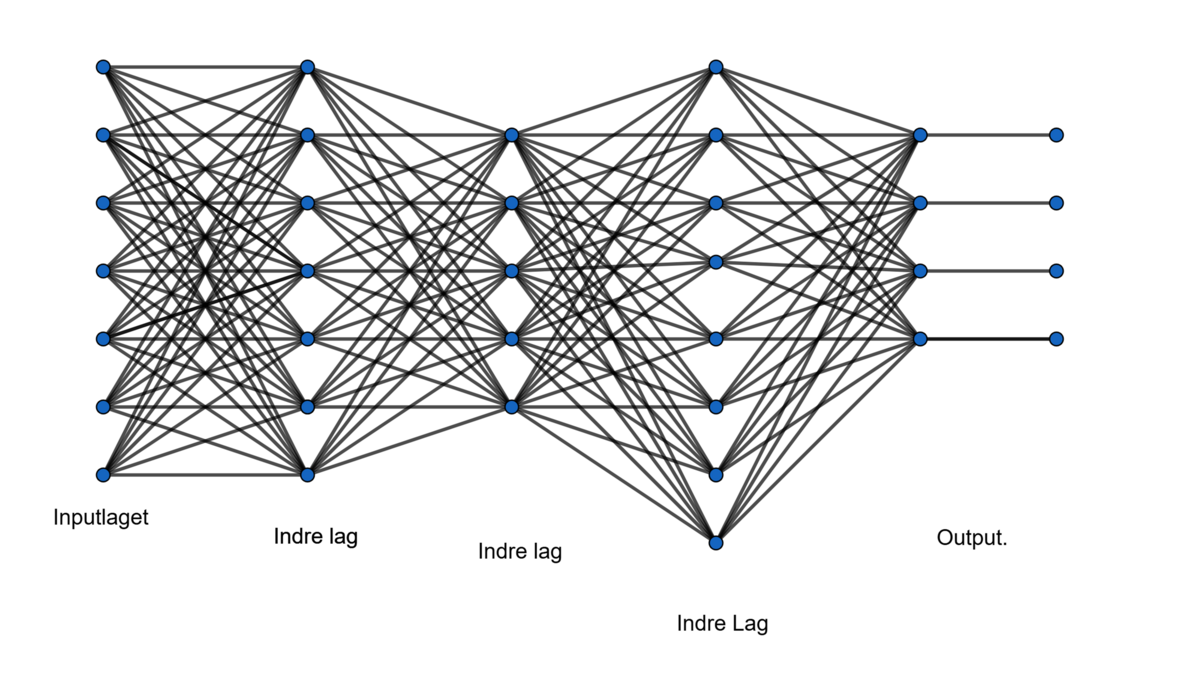
Figur 1 viser et eksempel på arkitekturen af et netværk. Man kan se, hvordan input, som fødes ind til venstre, gives videre gennem lagene. Man kan ikke se, hvad der sker i de enkelte lag. Der er tale om en omfattende, sammensat funktion, hvor hvert lag er en funktion, der anvender output fra det forrige lag som sit input.
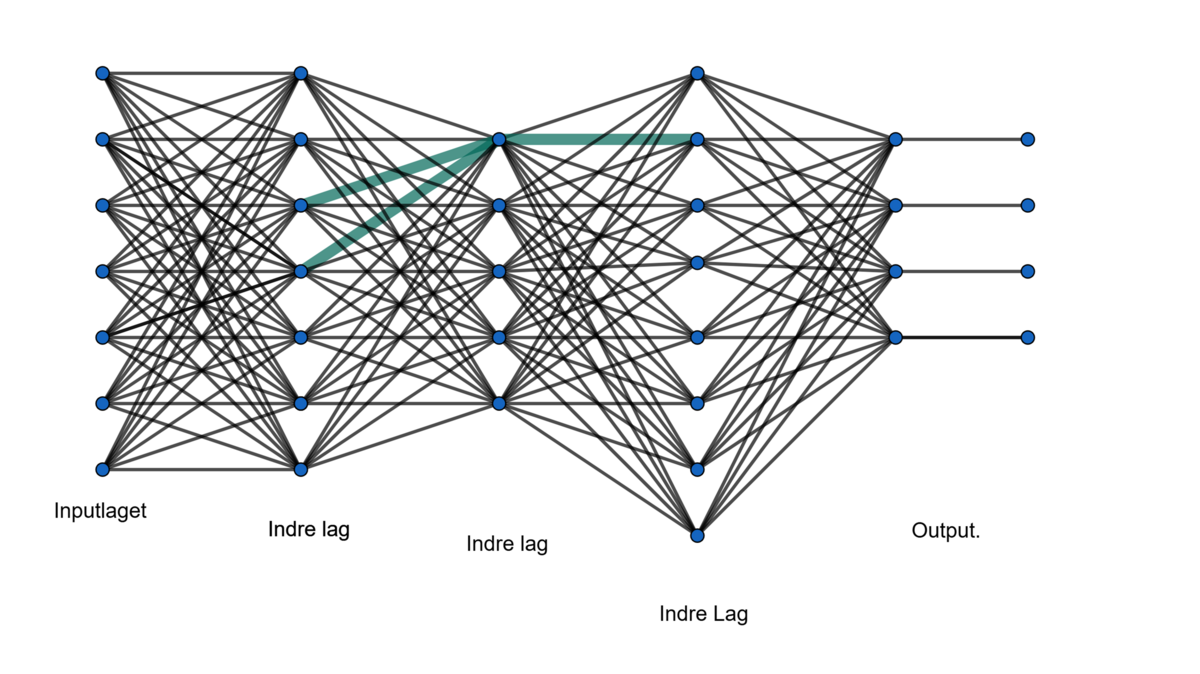
Vi fokuserer på den grønne del af netværket. Det er en enkelt kunstig neuron, som i det lille grønne udsnit har to input-variable og et output. Hver enkelt knude/neuron i netværket betragtes som en funktion. Hvis den modtager to input $x_1$ og $x_2$, beregner den en linearkombination $y=ax_1+bx_2$, hvor $a$ og $b$ er koefficienter (vægte). Det er netop disse vægte, man justerer på, når netværket trænes. Resultatet $y$ sættes derefter ind i en aktiveringsfunktion, eksempelvis sigmoid: $\sigma(y)=\frac{1}{1+e^{-y}}$.
$\sigma(y)$ er et tal mellem 0 og 1, så neuronens output ligger mellem 0 og 1. Det output er nu input til en eller flere af neuronerne i det næste lag. Alt i alt får man en funktion, som består af små dele, som hver for sig er simple.
Opgave
- Sæt $a=2$ og $b=5$ og udregn er $\sigma(2x_1+5x_2)$ for forskellige værdier af $(x_1,x_2)$.
- Prøv også med andre værdier af $a$ og $b$. Hvad sker der, hvis en af dem er 0?
Netværket giver, når man kender alle koefficienterne, altså en funktion, der ikke umiddelbart ligner dem, man ser i skolen – og så alligevel: Den får et input fra en inputmængde og giver et output, som er entydigt bestemt af input. Input til netværket/funktionen er ikke kun et enkelt tal, men mange tal. Et billede består for eksempel af mange pixelværdier, tal.
I et stort netværk som i figur 1 er der mange koefficienter. Hvis en neuron har 7 inputvariable, har den 7 koefficienter. For den grønne neuron er der, hvis man tager det hele med, 7 input (linjer ind fra venstre) og dens output går til 8 neuroner i det næste lag.
Under træningen justeres de mange koefficienter, så netværkets output så vidt som muligt svarer til de korrekte resultater i træningsdata.
Det overordnede princip
Vi vil gerne lave en funktion, der giver så korrekte output som muligt. Det gælder om at bestemme koefficienterne i funktionen. Det skal man gøre ved at benytte træningsdata som er data, hvor vi kender det korrekte svar.
Eksempel: Bedste rette linje
Ud fra data $(x_1, y_1)$, $(x_2,y_2)$, … , $(x_n,y_n)$ vil vi finde en ret linje $y=ax+b$, som minimerer summen af alle $(ax_i+b-y_i)^2$. Vi laver altså en funktion $f(x)=ax+b$, så summen af alle $(f(x_i)-y_i)^2$ bliver så lille som muligt. Derfor gælder det altså om at finde $a$ og $b$. Det svarer til et meget, meget lille neuralt netværk.
Når vi udregner summen af alle $(f(x_i)-y_i)^2$, er det et eksempel på en tabsfunktion $E(a,b,x_1,y_1,x_2,y_2,…,x_n,y_n)$. Den afhænger af $a$, $b$ og af træningsdata. Det gælder om at finde $a$, $b$, som minimerer $E(a,b,x_1,y_1,x_2,y_2,…,x_n,y_n)$.
Når vi har bestemt $a$ og $b$, har vi trænet netværket, og vi har et bud på en funktion $f(x)=ax+b$, som kan anvendes til at forudsige $y$-værdier for nye input $x$, der ikke indgår i træningsdata.
Fra træningsdata til funktion
På AI-mat kan man læse om, hvordan et simpelt neuralt netværk, perceptronen, som kun har et lag, finder en linje, der løser klassifikationsopgaven fra Klassificering og Geometri. Plot punkter i planen og giv dem to farver. Er der en linje, der opdeler planen i to, så de to typer punkter er på hver sin side af linjen? Er der mere end én linje? Og hvad man kan gøre, hvis der slet ikke er en linje, der deler data op.
Når vi har fundet linjen ud fra vores farvede datapunkter (træningsdata), har vi trænet vores lillebitte netværk. Når vi har linjen, kan vi finde farven på et nyt datapunkt, ved at se, hvilken side af linjen, dette punkt ligger på.
Træning af et neuralt netværk
Ovenfor er simple eksempler på træning af kunstige neurale netværk. Det generelle princip er det samme: Hvordan bygger man den funktion, der er gemt i et neuralt netværk? Det gælder om at bestemme koefficienterne i alle lagene og ved alle knuder. Det gør man ved hjælp af træningsdata, som er data, hvor man kender det korrekte svar. Man skal finde den funktion, der kommer tættest på at give det rigtige svar for træningsdata.
Man starter med en funktion, altså med et (tilfældigt) valg af koefficienter. Og opgaven er så at justere koefficienterne, så funktionen regner nogenlunde rigtigt på de eksempler, hvor vi kender facit. Ligesom vi så det for bedste rette linje. Neurale netværk har helt enormt mange koefficienter og trænes også på enorme mængder af data. Det kan lade sig gøre, fordi der er effektive metoder til opdatering af vægtene. Centralt er, at man ser på et netværk som en sammensat funktion og opdaterer vægte et lag ad gangen. Det kan man læse meget mere om på AI-mat. Der kan man bl.a. træne et lille netværk, hvor man kan bruge sine egne data. Læs mere her og se undervisningsforløb på AI-mat.
Træn dit eget neurale netværk:
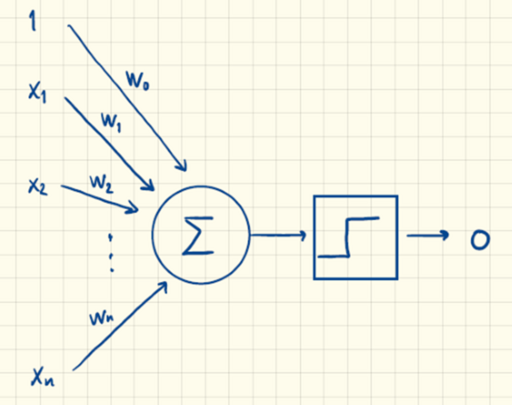
Et neuralt netværk, som kun har et lag, kan illustrere ideerne bag træning. På figur 3 er der kun én neuron. En kunstig neuron modtager inputvariable $x_1,x_2, ... ,x_n$. Der tilføjes et biasled $w_0$ og hvert input multipliceres med en vægt $w_i$. Summen heraf er input til den firkantede kasse, som er en valgt aktiveringsfunktion $S$, hvilket giver ”output” $o$ til højre. Output er $o = S(w_0+w_1x_1+w_2x_2+…+w_nx_n)$, hvor $S$ er aktiveringsfunktionen.
På AI-mat kan man finde en kunstig neuron app, som med input af en Excel-fil med træningsdata kan bestemme koefficienterne i sådan et lille netværk. Man skal vælge ”targetvariabel”, som er det, man gerne vil have output til at forudsige om et nyt datapunkt. For træningsdata kender man værdien af den variabel. Det kaldes targetværdien.
Eksempel
Funktionen $f(x1,x2)=\sigma(7+2x_1+5x_2)$ er et eksempel på et valg af koefficienterne $a=7$, $b=2$ og $c=5$ i $f_{(a, b, c)}(x_1,x_2)=\sigma(a+bx_1+cx_2)$. Som udgangspunkt kender vi ikke $a$, $b$ og $c$, men vi kender træningsdata. Træningsdata kan være 3 datapunkter med tilhørende ” rigtige svar”. Svarmulighederne er $0$ og $1$.
$(1,1)\rightarrow 0$, $(1,0)\rightarrow 0$, $(0,1)\rightarrow 1$
Eftersom vi kun har mulighederne $0$ og $1$ som korrekte svar, vælger ”maskinen” svaret $0$, hvis $f_{(a,b,c)}(x_1,x_2)<0.5$ og svaret $1$, hvis $f_{a,b,c}(x_1,x_2)\geq 0.5$. For at give et godt bud for ukendt data, er det faktisk ikke nok at svare korrekt på træningsdata, altså at $f_{(a,b,c)}(x_1,x_2)<0.5$, når svaret er $0$. Vi skal bestemme $a$, $b$, $c$, så $f_{(a,b,c)}(1,1)$ er tæt på $0$, $f_{(a,b,c)}(1,0)$ er tæt på $0$, og $f_{(a,b,c)}(0,1)$ er tæt på $1$.
Tæt på betyder her, at den samlede kvadratiske fejl,
$E(a,b,c) = (f_{(a,b,c)}(1,1)-0)^2+(f_{(a,b,c)}(1,0)-0)^2+(f_{(a,b,c)}(0,1)-1)^2$,
er mindst mulig.
Ved at bruge appen finder vi et godt bud på parametrene:
$a=0,3425$, $b=-3,914$, $c=1,533$
Lad os se på et simplere eksempel:
$g_{(a,b)}(x_1)=\sigma(a+bx_1)$
Træningsdata er
$g_{(a,b)}(1)=\sigma(a+b)=1$
$g_{(a,b)}(0)=\sigma(a)=0$
Så de fejl, vi laver, er hhv. $\sigma(a+b)-1$, og $\sigma(a)-0$.
Den samlede fejl skal være mindst mulig. Vi ser på den samlede kvadratiske fejl, som er en funktion af $a$ og $b$:
$E(a,b)=(\sigma(a+b)-1)^2+(\sigma(a)-0)^2$
Nu har vi en funktion af to variable, $a$ og $b$, som vi skal finde minimum for. Det gør man ved at differentiere og være smart. Noget af det smarte ligger i valget af aktiveringsfunktion. Der skal være en nem måde at udregne den afledte, når man kender funktionsværdierne: For sigmoid har vi
$\sigma'(x)=\sigma(x)(1-\sigma(x))$
Der er faktisk ikke kun ét minimum for funktionen, men appen giver et bud:
$a=-0.206$ og $b= 1.093$
Læs en grundig gennemgang for 3g A-niveau af matematikken som ligger bag her.
til: GRUNDSKOLE, GYMNASIE, ERHVERVSUDDANNELSE
emne: AI
UDGIVET: 2025